

The cml:shapes tag allows users to create an image annotation job for polylines in conjunction with a custom ontology and the use of test questions and aggregation.
Building a job
The following CML contains the possible parameters for a polylines job with labels:
<cml:shapes type="['line']" source-data="{{image_url}}" name="annotation" label="Annotate this image" validates="required" ontology="true" line-distance="10" line-threshold="0.7" line-agg="10" class-threshold="0.7" class-agg="agg" output-format="json" allow-image-rotation="true"/>
Note: There are parameters for test questions and aggregation that apply to both the polylines and the labels.
Parameters
Below are the parameters available for the cml:shapes tag. Some are required in the element, some can be left out.
-
type- The shape used in the job, set in an array.
-
To use multiple shapes in one job, include each shape in the array, separated by commas, e.g., 'type="['box','dot','polygon','line','ellipse']"'
- You’ll need to include the corresponding parameters for each shape
-
source-data- The column from your source data that contains the image URLs to be annotated.
-
name- The results header where annotations will be stored.
-
label- The question label contributors will see.
-
validates(optional)- Whether or not this element is required to be answered.
- Accepts ‘required’
- Defaults to not required if not present
-
ontology(optional)- The list of classes to be labeled in an image - view this article to learn how to create your custom ontology.
- Accepts a boolean
- Defaults to ‘false’ if not present
-
review-data(optional)-
This will read in existing annotations on an image. The format must match the output shown in the aggregation section below, with the exception of the class attribute (see example). All that’s needed is the following:
- ‘type’
- ‘class’ if using an ontology
- ‘coordinates’
- 'id'
- Example: [{“class”:“car”,"coordinates":[{"x":724,"y":359},{"x":1098,"y":244},{"x":1273,"y":495},{"x":903,"y":753}],“type”:“line”,“id”:“95a0b08c-b621-4dda-b983-967fe11e384e”}]
-
This will read in existing annotations on an image. The format must match the output shown in the aggregation section below, with the exception of the class attribute (see example). All that’s needed is the following:
-
line-distance- The maximum pixel distance between a golden line and a contributor line. We use the Fréchet Distance.
- Accepts an integer.
-
line-threshold- The minimum overall line IoU required for a contributor to pass a test question.
- Accepts a decimal value between 0.1 and 0.99.
-
The formula is correct / (correct + incorrect)
- Example: the line-threshold is set to 0.7 and a test question contains 10 ground truth shapes. A contributor gets 8 out of 10 classes correct for a score of 80% and they’re marked correct on the test question.
-
class-threshold- The minimum percentage of correct classes applied to polylnes in a test question for a contributor to be considered correct.
- Accepts a decimal value between 0.1 and 0.99.
-
The formula is correct / (correct + incorrect)
- Example: the line-threshold is set to 0.7 and a test question contains 10 ground truth shapes. A contributor gets 8 out of 10 classes correct for a score of 80% and they’re marked correct on the test question.
-
line-agg- The maximum pixel distance between result polylines to be clustered together, again this is the Fréchet Distance.
- Accepts an integer or the value 'all'.
-
class-agg- The aggregation applied to the class for a given cluster of shapes.
-
Accepts standard aggregation types:
aggallagg_xcagg_x
-
output-format(optional)- Accepts 'json' or 'url'
-
If ‘json’, the report column containing contributors' annotation data contains the annotation data in stringified JSON format. The JSON format is as follows (this is the legacy JSON format):
-
[
{
"id": "4bc1ba1d-ede9-4b80-9892-95fced615441",
"class": "Car",
"type": "box",
"coordinates": {
"x": 416,
"y": 243,
"w": 125,
"h": 95
}
}
]
-
-
If ‘url’, the report column containing contributors' annotation data contains links to files. Each file contains annotation data for a single data row in JSON format. With this new output option, we have updated the JSON structure to allow inclusion of more data fields. The new JSON format is as follows:
-
{
ableToAnnotate: true,
imageRotation: 30,
annotation: [{
"id": "4bc1ba1d-ede9-4b80-9892-95fced615441",
"class": "Car",
"type": "box",
"coordinates": {
"x": 416,
"y": 243,
"w": 125,
"h": 95
}
}]
}
-
- In the case where the tool was unable to load the input data and the contributor was unable to annotate,
ableToAnnotatewill be set tofalse. - Defaults to ‘json’ if attribute not present.
- This parameter is available within the CML only; it is not yet supported in the Graphical Editor.
-
allow-image-rotation(optional)- Accepts
trueorfalse -
If
true, contributors can rotate the image within the image annotation tool. Contributors click a toolbar icon to turn on a rotation slider that can be used to adjust rotation angle from 0 to 359 degrees. The degrees rotated are exported in theimageRotationfield. This feature is only compatible with export optionoutput-format=url; this attribute must be added to the job cml before launch.- Important note: Test questions and aggregation are not currently available for this annotation mode.
-
If
false, contributors cannot rotate the image. -
Defaults to
falseif attribute not present.
- Accepts
-
task-type(optional)- Please set task-type=”qa” when designing a review or QA job. This parameter needs to be used in conjunction with review-data . See this article for more details.
Shape Type Limiter
- Limit which shapes can be used with certain classes
Min/Max instance quantity
- Configure ontologies with instance limits
- Comes with the ability to mark the class as not present for long tail scenarios. This information will be added to the output as well.
Customizable Hotkeys
- Hotkeys can be assigned to classes by the user. Hotkeys cannot conflict with any other browser or tool shortcuts.
Creating test questions
When using the cml:shapes tag, the behavior of test questions and aggregation will change based on the shapes chosen and whether or not your job includes an ontology.
- On the quality page, click “Create Test Questions”
- Add annotations around the objects in the way you specified via your job's instructions.
- If no annotations are needed, make sure your job includes an option to hide the annotation tool.
- Save Test Question.
Reviewing test questions
- Select a test question from the quality page.
- From the image annotation sidebar, click ‘Find a Judgment’ and choose a contributor ID from the drop-down.
- Edit, create, or remove your own annotations based on feedback. Judgments are color coded based on if they match the gold responses.
- Each shape will have its own matching metrics, which you can see by hovering over a contributor judgment or golden shape. A notification will appear in the top left corner of the image. The pixel distance between the golden polyline and contributor polyline is shown. If using an ontology, the class match is also displayed.
- All scores on the image are averaged and compared to the test question threshold set in the job design. The overall matching score is then displayed in the left sidebar of the tool.
- Save any edits that are made to update the evaluation of the existing contributors' work and ensure any future attempts to answer the test question will be properly evaluated.
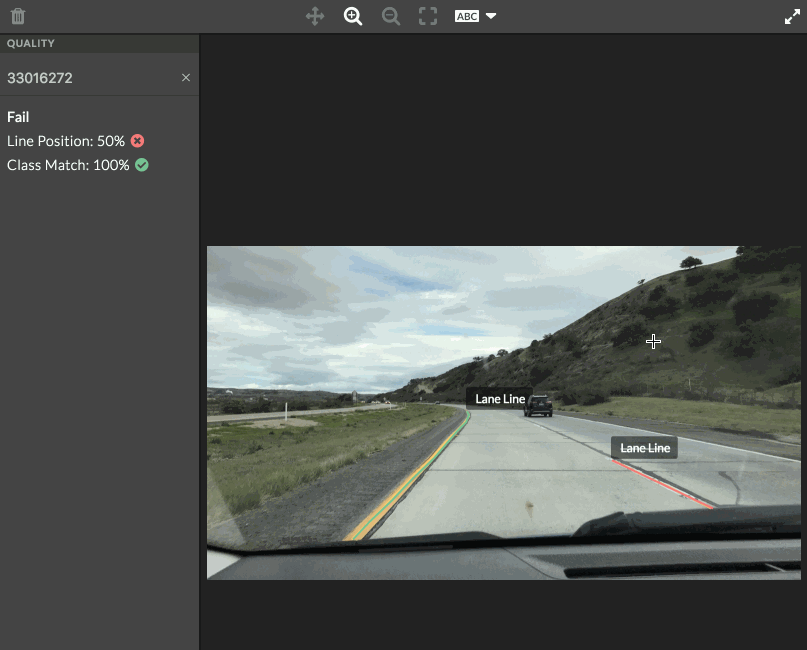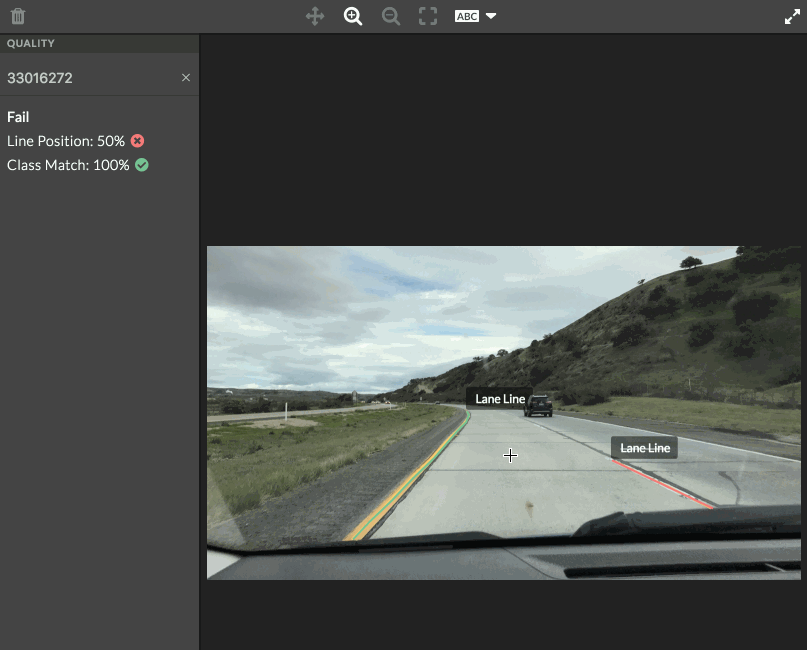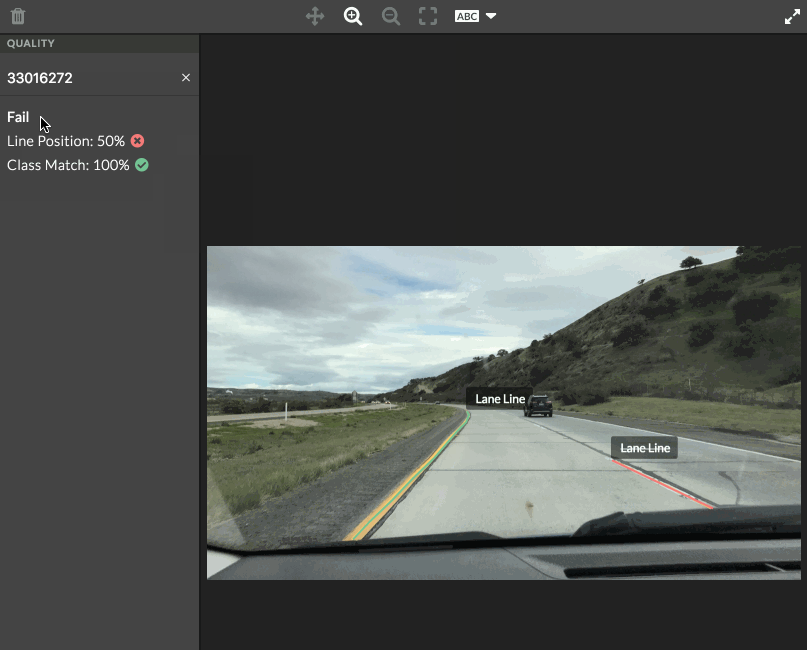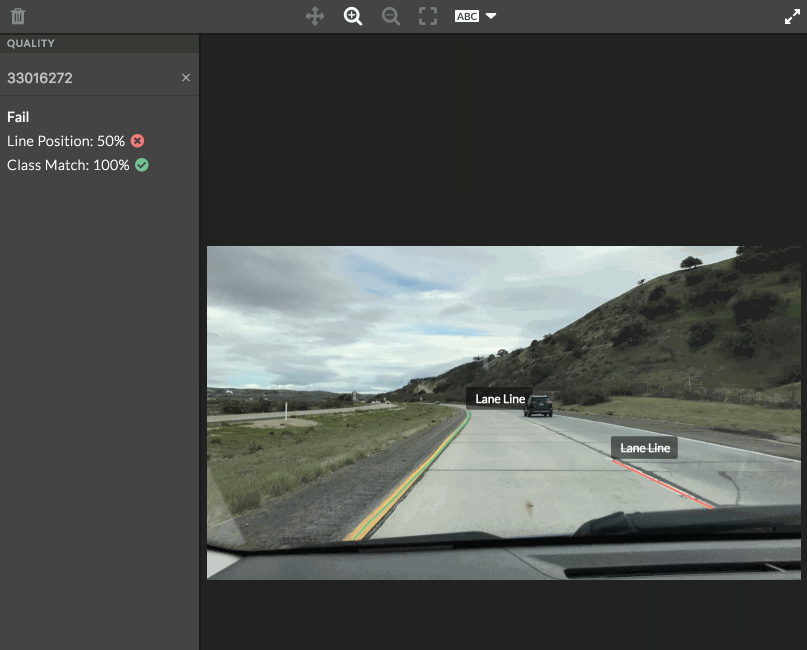
Fig. 1 test question scores
Aggregation
Polylines
Aggregation for polylines works as follows:
- Polylines are clustered based on pixel distance set in the 'line-agg' parameter.
- Each polyline in the cluster is divided into the same number of segments, creating the same number of anchor points for each polyline.
- The anchor points are weighted based on contributor trust scores, and a new anchor point is returned
- The averaged anchor points are connected to create a polyline.
Classes/labels
The class-agg parameter accepts the following standard aggregation methods:
aggallagg_xcagg_x
Labels (or classes) are aggregated per returned polyline. This means, for example, if you choose to aggregate polylines - as opposed to selecting 'all' - and you choose class-agg="agg", for each aggregated polyline you'd receive the most confident label out of the constituent polylines in the cluster. If you choose class-agg="all", you'd receive every label applied to the cluster of polylines, but still just one polyline, and so on. For line-agg="all", you'd receive every polyline and every label in the image, no aggregation. Labels will always be grouped with the shape they were applied to and will be returned in a dictionary.
Example output of a job with line-agg="0.6" and class-agg="agg":
[{"average_trust":0.9375,
"class":{"car":1.0},"coordinates":[{"x":724,"y":359},{"x":1098,"y":244},{"x":1273,"y":495},{"x":903,"y":753}],"type":"line"}]
Example output of a job with line-agg="0.6" and class-agg="all":
[{"average_trust":0.9375,
"class":{"car":0.33,”person”:0.33,”tree”:0.33},"coordinates":[{"x":724,"y":359},{"x":1098,"y":244},{"x":1273,"y":495},{"x":903,"y":753}],"type":"line"}]
Reviewing results
To review the results of your job, you can either use our In-Platform Audit feature (recommended), or the following:
- Go to the Data page.
- Click on a unit ID.
- In the sidebar of the annotation tool, select an option from the drop down menu.
- You’ll see different contributor IDs, which allow you to view individual annotations.
- You’ll also see an “aggregated” option, which shows you the result you’ll get based on your aggregation settings in the CML or report options page of your job.